The second day started with breakfast and coffee in the Waterfront, Stockholm, Sweden.

CloudState—Towards Stateful Serverless
This session was presented by Jonas Bonér, Lightbend Inc. (jboner).
The Serverless experience is revolutionary and will grow to dominate the future of Cloud Computing. Function-as-a-Service (FaaS) is, however—with its ephemeral, stateless, and short-lived functions—is only the first step. FaaS is great for processing-intensive, parallelizable workloads, moving data from A to B providing enrichment and transformation along the way. But it is quite limited and constrained in what use-cases it addresses well, which makes it very hard/inefficient to implement general-purpose application development and distributed systems protocols.
What’s needed is a next-generation Serverless platform and programming model for general-purpose application development in the new world of real-time data and event-driven systems. What is missing is ways to manage distributed state in a scalable and available fashion, support for long-lived virtual stateful services, ways to physically co-locate data and processing, and options for choosing the right data consistency model for the job.
Cloudstate is an open-source Apache project. Cloudstate is a specification, protocol, and reference implementation for providing distributed state management patterns suitable for Serverless computing. The current supported and envisioned patterns include:
- Event Sourcing
- Conflict-Free Replicated Data Types (CRDTs)
- Key-Value storage
- P2P messaging
- CQRS read side projections
Cloudstate makes stateful serverless application easy and lets’ the use focus on the business logic, data model and workflow.
- Services in any language that supports gRPC, and with language-specific libraries provided that allow idiomatic use of the patterns in each language is supported by Cloudstate, that makes this polyglot. Cloudstate can be used either by itself, in combination with a Service Mesh, or it is in envisioned that it will be integrated with other Serverless technologies
- Cloudstate is Polystate, as it is based on Powerful state models—Event Sourcing, CRDTs, Key-Value
- Cloudstate is PolyDB, Supports SQL, NoSQL, NewSQL and in-memory replication
- Leveraging Akka, gRPC, Knative, GraalVM, running on Kubernetes
In short, Cloudstate manages:
- Complexities of Distributed and Concurrent systems
- Distributed State—Consistency, Replication, Persistence
- Databases, Service Meshes, and other infrastructure
- Message Routing, Scalability, Fail-over & Recovery
- Running & Operating your application
High Level Architecture
The Cloudstate reference implementation is built on top of Kubernetes, Knative, Graal VM, gRPC, and Akka, with a growing set of client API libraries for different languages. Inbound and outbound communication is always going through the sidecars over gRPC channel using a constrained and well-defined protocol, in which the user defines commands in, events in, command replies out, and events out. Communicating over a gRPC allows the user code to be implemented in different languages (JavaScript, Java, Go, Scala, Python, etc.) [Reference].
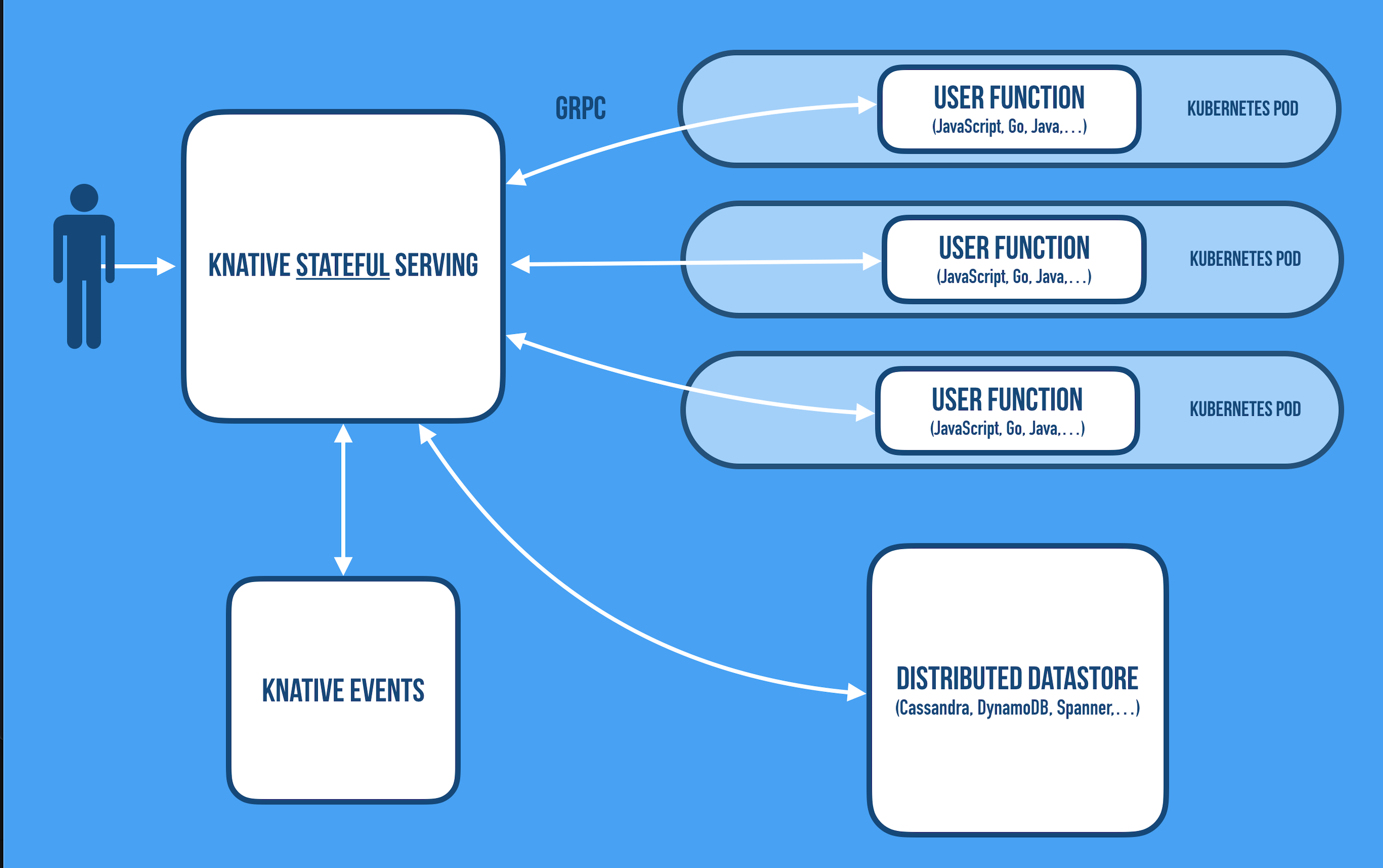
The stateful service is supported by Akka cluster having Akka actors. The user, however doesn’t go through all the complexities and protected by Akka sidecars which interact the user code with the backend state and cluster management.

The Hacker’s Guide to JWT Security
This session was conducted by Patrycja Wegrzynowicz, Yon Labs, (yonlabs)
JSON Web Token (JWT) is an open standard for creating tokens that assert some number of claims like a logged-in user and his/her roles. JWT is widely used in modern applications as a stateless authentication mechanism. Therefore, it is important to understand JWT security risks, especially when broken authentication is among the most prominent security vulnerabilities according to the OWASP Top 10 list.
JSON Web Token (JWT) is an open standard (RFC 7519) that defines a compact and self-contained way for securely transmitting information between parties as a JSON object. This information can be verified and trusted because it is digitally signed. JWTs can be signed using a secret (with the HMAC algorithm) or a public/private key pair using RSA or ECDSA [Reference].
This session was based on four demos, each demo showed how a JWT can be hacked and used by others with different algorithms. Those demos explained various security risks of JWT, including confidentiality problems, vulnerabilities in algorithms and libraries, token cracking, token sidejacking, and more. These demos also showed common mistakes and vulnerabilities along with the best practices related to the implementation of JWT authentication and the usage of available JWT libraries.
Recommendations based on those demos:
- Know your JWT library
- Always use a specific algorithm and a key during verification
- Always set an expiration time
- Use algorithm with higher bit size
Living on the Cloud’s Edge
This session was presented by Rustam Mehmandarov, Computas AS, (rmehmandarov) and Tannaz N. Roshandel, University of Oslo (tannaznvr)
Edge computing helps to break beyond the limitations imposed by, now, traditional cloud solutions. Some of the reasons might be privacy concerns, reducing the need for heavy processing resources, reducing the amount of data that is sent over the network – just to mention a few.
IoT Edge is a layer between Fog and IoT. Fog is the network to transfer data. Edge computing is computing that’s done at or near the source of the data, instead of relying on the cloud at one of a dozen data centers to do all the work.

In the live demo, they used a system built using the Google Coral IoT Edge device. That was an example to process video streams on the Edge and designed to keep the privacy of the people intact; without leaking faces and identity of the people to a 3rd party.
Organisation Refactoring and Culture Hacking – Lessons from Software
This session was presented by Andrew Harmel-Law, ThoughtWorks, (al94781).
This session was based on a case study of the presenter. Where presenter was promoted to the manager level to manage a big group of people. He faced difficulties, in the beginning, to manage the workload because of different queries and requests to attend different courses/conferences via email. In the beginning, he decided to forward all mails to his HR department. Soon after this, he started receiving queries from the HR department about the technical courses and conferences which required approval of the manager. That brought him back to the original problem he was facing.
According to the presenter:
“Hacking teams is almost as much fun as hacking code”
- The organization structure is best served by being in a constant state of (incremental) change.
- The best people to drive these changes are those closest to the action – us, the makers.
- Our existing maker skills are ideally suited for this work.
Refactoring and hacking is based on five steps
I. Map the Human Architecture: Group different roles and skills in a circle based on purpose and perspective. In this regard don’t overestimate existing understanding of how the org works. It’s a map of existing power and influence. Openness builds trust so be transparent and open to the staff.
II. Read the Dynamic System: Add a default response if there is a query or request of same pattern. In this regards, presenter gave the example that he auto approved the request for certain courses and conferences to reduce the load of replying each query.
III. Make the Right Change: Sometimes, a small change can have a huge impact. Observe the whole dynamic system and maintain the quality. Always watch out for feedback.
IV. Kill Consensus: To kill consensus, anyone can make any decision, after seeking advice from everyone who will be meaningfully affected, and those with expertise discuss the solution with experts even if they have done things a long time ago.
V. Beyond Delegation: This is based on the Toyota way of working. The manager should put responsibilities on the staff he/she is managing. The manager should not disappear, but start disappearing to let people take responsibilities. It’s all about power, the more power to take the decision to be given to the employees they will take more responsibilities. Devolution beats delegations, which means that spreading the problem with the staff rather than imposing the solution on them
Power is normally shared between managers and leaders, they should mentor the people to let them make the decision on their own. This will help in building the confidence of the people. It is safer to transfer power in a trustworthy way. Right changes in an end-to-end dynamic system are important to make some tiny tiny improvements. These improvements are meant for everyone not for any specific individual.
To improve the roles and groups, invite co-owners, new owners and show confidence in let them make changes. Let the hierarchy emerge as, where and when required
Refactoring or hack, doesn’t matter if things are improving
Globally Distributed SQL Databases FTW
This session was presented by Henrik Engström, Kindred Group, (h3nk3).
When Google published the paper “F1: A Distributed SQL Database That Scales” in 2013 it set off a new type of database referred to as “Distributed SQL Databases”. The premise was to be able to use ACID transactions in a truly distributed database – something that was considered a pipedream before then. The main driver for F1, which has served as a model for several on-prem and cloud-based offsprings, was that Google realized that their engineers’ built systems were error-prone and overly complex when using eventual consistency.

Personally, I have invested a non-trivial portion of my career as a strong advocate for the implementation and use of platforms providing guarantees of global serializability.
Life beyond Distributed Transactions: an Apostate’s Opinion [2007]
The evolution of consistency from strong to eventual consistency is based on the ACID definition.
In strong consistency, consistency is associated with RDBMS and ACID is
– Atomicity – all or nothing
– Consistency – no violating constraints
– Isolation – exclusive access
– Durability – committed data survives crashes
In eventual consistency, consistency is associated with No SQL, and ACID is
– Associative – Set().add(1).add(2) === Set().add(2).add(1)
– Commutative – Math.max(1,2) === Math.max(2,1)
– Idempotent – Map().put(“a”,1).put(“a”,1) === Map().put(“a”,1)
– Distributed – symbolical meaning’

CockroachDB – inspired by F1/Spanner and used at Kindred – to see how one can implement systems using a globally distributed database that simultaneously provides developers with ACID properties.
- CockroachDB scales horizontally without reconfiguration or need for a massive architectural overhaul. Simply add a new node to the cluster and CockroachDB takes care of the underlying complexity.
- CockroachDB allows you to deploy a database on-prem, in the cloud or even across clouds, all as a single store. It is a simple and straightforward bridge to your future, cloud-based data architecture.
- CockroachDB delivers an always-on and available database designed so that any loss of nodes is consumed without impact to availability. It creates & manages replicas of your data to ensure reliability.
- CockroachDB is the only database in the world that enables you to attach ‘location’ to your data at the row level. This capability allows you to regulate the distance between your users and their data.

Performance
This session was conducted by Chris Thalinger, Twitter, (christhalinger) and this was a quickie i.e. of 15 minutes.
In today’s Software Development world the number one demand from employers is to deliver features as soon as possible. Everything else is secondary. That means engineers are doing only one thing: writing new code, debugging, and writing new code again. And most of the time this code is running in one of the very convenient clouds. Rarely anyone ever stops and thinks about performance as a whole. If performance is an issue the to-go solution is to throw more money at it. Which usually means buying more computing power in the cloud. Adding more computing becomes wasteful and non-environment friendly. We should find out how to optimize the code to avoid this wasteful.
The presenter presented different companies like Google, Microsoft, AMAZON, and Twitter about how they use renewable energy and trying to reduce waste.
STOP EVERY NOW AND THEN AND THINK ABOUT THE IMPACT OF YOUR WORK
Lessons Learned from the 737 Max
This session was presented by Ken Sipe, D2iQ (kensipe).
There were two fatal crashes of the Boeing 737 Max in the fall of 2018 and spring of 2019 grounding the airplane worldwide and begging the question of why? In the end, it comes down to software but there is much more to that story. [Redacted], the presenter in this session was in the unique position of being an instrument-rated private pilot and a software engineer with experience working with remote teams, both will provide insight into lessons we will learn as we peel back the details of these tragic events.
In this session, the presenter presented about aircraft types and how they affect decisions of the airline industry from pilot scheduling, plane schedules, innovation, and profits. An airplane design from 1994 causes challenges in 2018-2019 that resulted in a software solution to a hardware problem of design. The presenter presented different rules and regulations from USA FAA relinquishing quality standards to Boeing because of man-power and costs. This session also focused on what a pilot does and expects and what the MCAS system did by design.
Lessons from this study learned are:
- Fail-safe: fail-safe is better than foolproof. Failing safe allows users to undo when they do anything wrong. Provide cross-checks, which was missing in the case of 737 Max.
- Provide all necessary warnings to the end-user. In this case, these were disabled and pilots were not able to see the warning.
- Reduce workload: The workload was one reason to have faulty software. High workload may result in task drop or less task performance.
- Safety is assumed: Make it part of your requirements.
- Politics: Be aware when requirements are not technical
- Documentation: Documentation is essentially required and it very important to give importance to documentation.
- Cheap is expensive: The development was done at a very cheap rate and no senior developer was involved. To have reliable software don’t go only for the cheap developers.




































You must be logged in to post a comment.